W modelowaniu statystycznym analiza regresji jest badaniem stosowanym do oceny związku między zmiennymi. Ta metoda matematyczna obejmuje wiele innych metod modelowania i analizy kilku zmiennych, gdy skupia się na związku między zmienną zależną a jedną lub większą liczbą niezależnych. Mówiąc dokładniej, analiza regresji pomaga zrozumieć, jak zmienia się typowa wartość zmiennej zależnej, jeśli zmienia się jedna z zmiennych niezależnych, podczas gdy pozostałe zmienne niezależne pozostają stałe.

We wszystkich przypadkach oszacowanie docelowe jest funkcją zmiennych niezależnych i nazywa się funkcją regresji. W analizie regresji warto również scharakteryzować zmianę zmiennej zależnej jako funkcję regresji, którą można opisać za pomocą rozkładu prawdopodobieństwa.
Zadania analizy regresji
Ta metoda badań statystycznych jest szeroko stosowana do prognozowania, gdzie jej stosowanie ma znaczącą przewagę, ale czasami może prowadzić do złudzeń lub fałszywych związków, dlatego zaleca się ostrożne stosowanie jej w tym temacie, ponieważ na przykład korelacja nie oznacza związku przyczynowego.
Opracowano wiele metod przeprowadzania analizy regresji, takich jak regresja liniowa i zwykła metoda najmniejszych kwadratów, które są parametryczne. Ich istotą jest to, że funkcja regresji jest zdefiniowana w kategoriach skończonej liczby nieznanych parametrów, które są szacowane na podstawie danych. Regresja nieparametryczna pozwala jej funkcjom leżeć w pewnym zestawie funkcji, które mogą być nieskończenie wymiarowe.
Jako metoda badań statystycznych analiza regresji w praktyce zależy od formy procesu generowania danych i tego, w jaki sposób odnosi się do metody regresji. Ponieważ prawdziwą formą procesu przetwarzania danych jest z reguły nieznana liczba, analiza regresji danych często zależy w pewnym stopniu od założeń dotyczących tego procesu. Te założenia są czasami weryfikowane, jeśli jest wystarczająca ilość danych. Modele regresji są często przydatne, nawet gdy założenia są umiarkowanie naruszane, chociaż nie mogą działać z maksymalną wydajnością.
W węższym znaczeniu regresja może odnosić się konkretnie do oceny zmiennych odpowiedzi ciągłej, w przeciwieństwie do zmiennych dyskretnych stosowanych w klasyfikacji. Przypadek ciągłej zmiennej wyjściowej nazywany jest również regresją metryczną w celu odróżnienia jej od powiązanych problemów.
Historia
Najwcześniejszą formą regresji jest dobrze znana metoda najmniejszych kwadratów. Został opublikowany przez Legendre w 1805 r., A Gauss w 1809 r. Legendre i Gauss zastosowali tę metodę do zadania polegającego na określeniu z obserwacji astronomicznych orbit ciał wokół Słońca (głównie komet, ale później nowo odkrytych mniejszych planet). Gauss opublikował dalszy rozwój teorii najmniejszych kwadratów w 1821 roku, w tym wersję twierdzenia Gaussa-Markowa.

Termin „regresja” został wymyślony przez Francisa Galtona w XIX wieku w celu opisania zjawiska biologicznego. Najważniejsze było to, że wzrost potomków od wzrostu przodków z reguły spada do normalnej średniej.Dla Galtona regresja miała tylko to znaczenie biologiczne, ale później jego prace były kontynuowane przez Udneya Yule i Karla Pearsona i przeniesione do bardziej ogólnego kontekstu statystycznego. W pracach Yule i Pearson wspólny rozkład zmiennych odpowiedzi i zmiennych objaśniających jest uważany za gaussowski. To założenie zostało odrzucone przez Fishera w pracach z 1922 i 1925 r. Fisher zasugerował, że rozkład warunkowy zmiennej odpowiedzi jest gaussowski, ale łączny rozkład nie powinien być. Pod tym względem założenie Fischera jest bliższe sformułowaniu Gaussa z 1821 r. Do 1970 r. Uzyskanie analizy regresji zajmowało niekiedy nawet 24 godziny.

Metody analizy regresji są nadal obszarem aktywnych badań. W ostatnich dziesięcioleciach opracowano nowe metody niezawodnej regresji; regresja obejmująca skorelowane odpowiedzi; metody regresji uwzględniające różne rodzaje brakujących danych; regresja nieparametryczna; Metody regresji bayesowskiej; regresje, w których zmienne predykcyjne są mierzone z błędem; regresje z większą liczbą predyktorów niż obserwacje, a także wnioskowanie przyczynowe z regresją.
Modele regresji
Modele analizy regresji obejmują następujące zmienne:
- Nieznane parametry, oznaczone jako beta, które mogą być skalarem lub wektorem.
- Niezależne zmienne, X.
- Zmienne zależne, Y.
W różnych dziedzinach nauki, w których stosuje się analizę regresji, stosowane są różne terminy zamiast zmiennych zależnych i niezależnych, ale we wszystkich przypadkach model regresji odnosi Y do funkcji X i β.
Przybliżenie zwykle przyjmuje postać E (Y | X) = F (X, β). Aby przeprowadzić analizę regresji, należy określić typ funkcji f. Rzadziej opiera się na wiedzy o związku między Y i X, które nie opierają się na danych. Jeśli taka wiedza nie jest dostępna, wówczas wybierana jest elastyczna lub wygodna forma F.
Zmienna zależna Y
Załóżmy teraz, że wektor o nieznanych parametrach β ma długość k. Aby przeprowadzić analizę regresji, użytkownik musi podać informacje o zmiennej zależnej Y:
- Jeśli istnieją N punktów danych w postaci (Y, X), w których N
- Jeśli zaobserwowano dokładnie N = K, a funkcja F jest liniowa, równanie Y = F (X, β) można rozwiązać dokładnie, a nie w przybliżeniu. Sprowadza się to do rozwiązania zestawu równań N z N-nieznanymi (elementami β), który ma unikalne rozwiązanie, o ile X jest liniowo niezależny. Jeśli F jest nieliniowe, rozwiązanie może nie istnieć lub może istnieć wiele rozwiązań.
- Najczęstszą jest sytuacja, w której obserwuje się N> punktów do danych. W takim przypadku w danych jest wystarczająca ilość informacji, aby oszacować unikalną wartość β, która najlepiej pasuje do danych, a model regresji, gdy zastosowany do danych, można uznać za system o zbyt dużym ustaleniu w β.
W tym drugim przypadku analiza regresji zapewnia narzędzia do:
- Znalezienie rozwiązań dla nieznanych parametrów β, które na przykład zminimalizują odległość między zmierzonymi a przewidywanymi wartościami Y.
- Przy pewnych założeniach statystycznych analiza regresji wykorzystuje informacje o nadmiarze w celu uzyskania informacji statystycznych o nieznanych parametrach β i przewidywanych wartościach zmiennej zależnej Y.
Niezbędna liczba niezależnych pomiarów
Rozważ model regresji, który ma trzy nieznane parametry: β0, β1 i β2. Załóżmy, że eksperymentator wykonuje 10 pomiarów przy tej samej wartości zmiennej niezależnej wektora X.W takim przypadku analiza regresji nie zapewnia unikalnego zestawu wartości. Najlepszą rzeczą, jaką możesz zrobić, jest ocena średniej i odchylenia standardowego zmiennej zależnej Y. Mierząc dwie różne wartości X w ten sam sposób, możesz uzyskać wystarczającą ilość danych dla regresji z dwiema niewiadomymi, ale nie dla trzech lub więcej niewiadomych.

Jeśli pomiary eksperymentatora zostały przeprowadzone przy trzech różnych wartościach zmiennej niezależnej wektora X, wówczas analiza regresji dostarczy unikalnego zestawu oszacowań dla trzech nieznanych parametrów w β.
W przypadku ogólnej regresji liniowej powyższe stwierdzenie jest równoważne wymogowi macierzy XT.X jest odwracalny.
Założenia statystyczne
Gdy liczba pomiarów N jest większa niż liczba nieznanych parametrów k i błąd pomiaru εja, następnie z reguły nadmiar informacji zawartych w pomiarach jest następnie dystrybuowany i wykorzystywany do prognoz statystycznych dotyczących nieznanych parametrów. Ten nadmiar informacji nazywa się stopniem swobody regresji.
Podstawowe założenia
Klasyczne założenia do analizy regresji obejmują:
- Próbka jest reprezentatywna dla przewidywania wnioskowania.
- Błąd jest zmienną losową o średniej wartości zero, która jest zależna od zmiennych objaśniających.
- Zmienne niezależne mierzone są bezbłędnie.
- Jako zmienne niezależne (predyktory) są one liniowo niezależne, co oznacza, że nie można wyrazić żadnego predyktora w postaci liniowej kombinacji pozostałych.
- Błędy są nieskorelowane, tj. Macierz kowariancji błędów diagonalnych, a każdy niezerowy element stanowi wariancję błędu.
- Wariancja błędu jest stała zgodnie z obserwacjami (homoskedastyczność). Jeśli nie, możesz użyć metody ważenia metodą najmniejszych kwadratów lub innych metod.
Te wystarczające warunki do oszacowania metodą najmniejszych kwadratów posiadają wymagane właściwości, w szczególności te założenia oznaczają, że oszacowania parametrów będą obiektywne, spójne i skuteczne, zwłaszcza jeśli zostaną uwzględnione w klasie oszacowań liniowych. Należy zauważyć, że dowody rzadko spełniają warunki. Oznacza to, że metoda jest stosowana, nawet jeśli założenia nie są prawdziwe. Różnorodność założeń może być czasem stosowana jako miara przydatności tego modelu. Wiele z tych założeń można złagodzić za pomocą bardziej zaawansowanych metod. Raporty z analizy statystycznej zazwyczaj obejmują analizę testów na podstawie danych przykładowych i metodologii użyteczności modelu.
Ponadto zmienne w niektórych przypadkach odnoszą się do wartości zmierzonych w lokalizacjach punktowych. Mogą występować trendy przestrzenne i autokorelacja przestrzenna w zmiennych, które naruszają założenia statystyczne. Regresja ważona geograficznie jest jedyną metodą, która zajmuje się takimi danymi.
Analiza regresji liniowej
W regresji liniowej cechą jest zmienna zależna, którą jest Yjajest liniową kombinacją parametrów. Na przykład w prostej regresji liniowej do modelowania n-punktów stosuje się jedną zmienną niezależną xjai dwa parametry, β0 i β1.
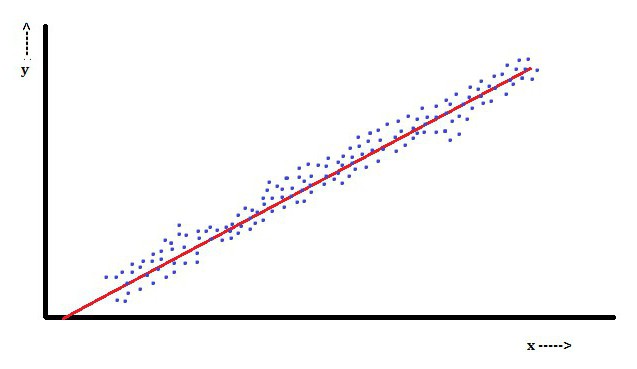
Dzięki wielokrotnej regresji liniowej istnieje kilka niezależnych zmiennych lub ich funkcji.
Przy losowym próbkowaniu z populacji jego parametry pozwalają uzyskać model regresji liniowej.
W tym aspekcie najpopularniejsza jest metoda najmniejszych kwadratów. Za jego pomocą uzyskuje się oszacowania parametrów, które minimalizują sumę kwadratów reszt. Ten rodzaj minimalizacji (która jest charakterystyczna dla regresji liniowej) tej funkcji prowadzi do zestawu równań normalnych i zestawu równań liniowych z parametrami rozwiązanymi w celu uzyskania oszacowań parametrów.
Przy dalszym założeniu, że błąd populacji zwykle się rozprzestrzenia, badacz może wykorzystać te szacunkowe błędy standardowe do stworzenia przedziałów ufności i przetestowania hipotez dotyczących jego parametrów.
Analiza regresji nieliniowej
Przykład, w którym funkcja nie jest liniowa w stosunku do parametrów, wskazuje, że sumę kwadratów należy zminimalizować za pomocą procedury iteracyjnej. Wprowadza to wiele komplikacji, które determinują różnice między liniowymi i nieliniowymi metodami najmniejszych kwadratów. W rezultacie wyniki analizy regresji przy użyciu metody nieliniowej są czasami nieprzewidywalne.
Obliczanie mocy i wielkości próby
Tutaj z reguły nie ma spójnych metod dotyczących liczby obserwacji w porównaniu z liczbą zmiennych niezależnych w modelu. Pierwsza zasada została zaproponowana przez Gooda i Hardina i wygląda jak N = t ^ n, gdzie N jest rozmiarem próby, n jest liczbą zmiennych niezależnych, zaś t jest liczbą obserwacji niezbędnych do osiągnięcia pożądanej dokładności, jeśli model miał tylko jedną zmienną niezależną. Na przykład naukowiec buduje model regresji liniowej przy użyciu zestawu danych zawierającego 1000 pacjentów (N). Jeśli badacz zdecyduje, że do dokładnego określenia linii (m) potrzeba pięciu obserwacji, maksymalna liczba zmiennych niezależnych obsługiwanych przez model wynosi 4.
Inne metody
Pomimo tego, że parametry modelu regresji są zwykle szacowane przy użyciu metody najmniejszych kwadratów, istnieją inne metody, które są używane znacznie rzadziej. Na przykład są to następujące metody:
- Metody bayesowskie (np. Metoda regresji liniowej bayesowskiej).
- Regresja procentowa stosowana w sytuacjach, w których zmniejszenie procentowych błędów jest uważane za bardziej odpowiednie.
- Najmniejsze odchylenia bezwzględne, które są bardziej stabilne w przypadku wartości odstających prowadzących do regresji kwantowej.
- Regresja nieparametryczna, wymagająca dużej liczby obserwacji i obliczeń.
- Odległość metryki uczenia się, która jest badana w poszukiwaniu znacznej odległości metryki w danej przestrzeni wejściowej.
Oprogramowanie
Wszystkie główne pakiety oprogramowania statystycznego są wykonywane przy użyciu analizy regresji metodą najmniejszych kwadratów. Prosta regresja liniowa i analiza regresji wielokrotnej może być stosowana w niektórych aplikacjach arkuszy kalkulacyjnych, a także w niektórych kalkulatorach. Chociaż wiele pakietów oprogramowania statystycznego może wykonywać różne typy nieparametrycznej i niezawodnej regresji, metody te są mniej znormalizowane; różne pakiety oprogramowania wdrażają różne metody. Opracowano specjalistyczne oprogramowanie do regresji do użytku w takich obszarach, jak analiza badania i neuroobrazowanie.






