Betydelsenivån i statistiken är en viktig indikator som återspeglar graden av förtroende för noggrannheten och sanningen för de mottagna (förutspådda) uppgifterna. Konceptet används allmänt inom olika områden: från att utföra sociologisk forskning, till statistisk testning av vetenskapliga hypoteser.

definition
Nivån för statistisk signifikans (eller statistiskt signifikant resultat) visar vad som är sannolikheten för en oavsiktlig förekomst av de studerade indikatorerna. Fenomenets allmänna statistiska betydelse uttrycks av koefficienten p-värde (p-nivå). I alla experiment eller observationer är det troligt att de erhållna data beror på samplingsfel. Detta gäller särskilt för sociologi.
Det vill säga en statistik är statistiskt signifikant vars sannolikhet för oavsiktlig händelse är extremt liten eller tenderar till ytterligheter. Extrem i detta sammanhang anses graden av avvikelse av statistik från nollhypotesen (en hypotes som kontrolleras för överensstämmelse med erhållna provdata). I vetenskaplig praxis väljs signifikansnivån före datainsamlingen och som regel är koefficienten 0,05 (5%). För system där exakta värden är oerhört viktiga kan denna indikator vara 0,01 (1%) eller mindre.
anamnes
Begreppet signifikansnivå infördes av den brittiska statistikern och genetikern Ronald Fisher 1925 när han utvecklade en metod för att testa statistiska hypoteser. Vid analys av en process finns det en viss sannolikhet för vissa fenomen. Svårigheter uppstår när man arbetar med små (eller inte uppenbara) procentsannolikheter som faller under begreppet "mätfel."
När man arbetade med statistik som inte är tillräckligt specifik för att verifiera, mötte forskare problemet med nollhypotesen, som ”stör” med små mängder. Fisher föreslog att man definierar för sådana system sannolikhet för händelser 5% (0,05) som en bekväm selektiv skiva, så att du kan avvisa nollhypotesen i beräkningarna.
Införande av en fast koefficient
1933 rekommenderade forskarna Jerzy Neumann och Egon Pearson i sina arbeten i förväg (innan datainsamlingen) för att fastställa en viss nivå av betydelse. Exempel på användning av dessa regler syns tydligt under valet. Anta att det finns två kandidater, varav en är mycket populär, och den andra är lite känd. Det är klart att den första kandidaten vinner valet och chanserna för den andra tenderar att bli noll. De strävar efter - men inte lika: det finns alltid sannolikheten för force majeure, sensationell information, oväntade beslut som kan ändra de förutsagda valresultaten.
Neumann och Pearson enades om att Fishers föreslagna signifikansnivå på 0,05 (betecknad med symbolen α) är mest bekväm. Fisher själv 1956 motsatte sig emellertid fixeringen av detta värde. Han trodde att nivån på a borde fastställas i enlighet med specifika omständigheter. Till exempel i partikelfysiken är det 0,01.
Signifikansnivå av p-
Begreppet p-värde användes först i Brownleys arbete 1960. P-nivå (p-värde) är en indikator som är omvänt relaterad till resultatens sanning. Det högsta koefficient-p-värdet motsvarar den lägsta konfidensnivån i provet av beroende mellan variablerna.
Detta värde återspeglar sannolikheten för fel associerade med tolkningen av resultaten. Anta att p-nivå = 0,05 (1/20). Det visar sannolikheten för fem procent att förhållandet mellan variablerna som finns i provet bara är ett slumpmässigt drag i provet.Det vill säga, om detta beroende är frånvarande kan man med upprepade sådana experiment i genomsnitt i varje tjugonde studie förvänta sig samma eller större beroende mellan variablerna. Ofta betraktas p-nivån som "acceptabel marginal" för felnivån.
Förresten, p-värde kanske inte återspeglar det verkliga förhållandet mellan variablerna, utan visar bara ett visst medelvärde inom antagandena. I synnerhet kommer den slutliga analysen av data också att bero på de valda värdena för denna koefficient. Med en p-nivå = 0,05 kommer det att bli några resultat och med en koefficient på 0,01 andra.
Statistisk hypotesundersökning
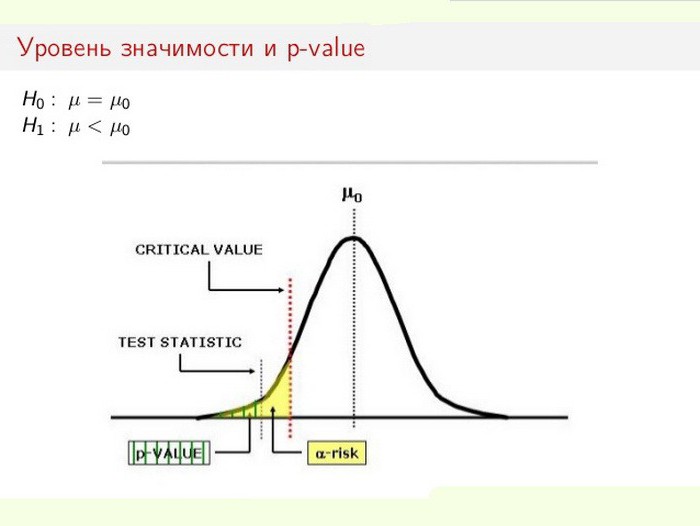
Nivån för statistisk betydelse är särskilt viktig när man testar hypoteser. Till exempel, vid beräkning av ett dubbelsidigt test delas avvisningsområdet lika i båda ändarna av provfördelningen (relativt nollkoordinaten) och dataens sanning beräknas.
Anta att när man övervakade en viss process (fenomen) visade det sig att den nya statistiska informationen indikerar små förändringar i förhållande till tidigare värden. Dessutom är skillnaderna i resultaten små, inte uppenbara, men viktiga för studien. Dilemmaet uppstår inför specialist: äger de verkliga förändringarna sig eller är dessa provtagningsfel (felaktiga mätningar)?
I det här fallet används eller avvisas nollhypotesen (allt hänförs till ett fel, eller så förändras systemet förändring som en fait accompli). Processen för att lösa problemet är baserad på förhållandet mellan total statistisk signifikans (p-värde) och signifikansnivå (α). Om p-nivån <α, avvisas nollhypotesen. Ju mindre p-värde, desto mer signifikant är teststatistiken.
Använda värden
Nivån av betydelse beror på materialet som analyseras. I praktiken används följande fasta värden:
- a = 0,1 (eller 10%);
- a = 0,05 (eller 5%);
- a = 0,01 (eller 1%);
- a = 0,001 (eller 0,1%).
Ju mer exakta beräkningarna krävs, desto lägre används koefficienten α. Naturligtvis kräver statistiska prognoser inom fysik, kemi, läkemedel, genetik större noggrannhet än inom statsvetenskap, sociologi.

Trösklar av relevans inom specifika områden
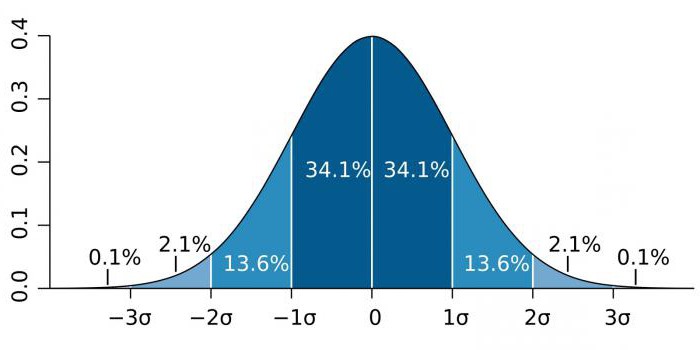
I områden med hög precision, såsom partikelfysik och tillverkningsaktiviteter, uttrycks statistisk betydelse ofta som förhållandet mellan standardavvikelsen (betecknad med sigma-koefficienten - σ) relativt den normala sannolikhetsfördelningen (Gaussisk distribution). σ är en statistisk indikator som bestämmer spridningen av värden för ett visst värde relativt matematiska förväntningar. Används för att plotta sannolikheten för händelser.
Beroende på kunskapsområdet varierar koefficienten σ mycket. Till exempel, när man förutsäger existensen av Higgs boson, är parametern σ fem (σ = 5), vilket motsvarar värdet p-värde = 1 / 3,5 miljoner.I studier av genom kan signifikansnivån vara 5 × 10-8som inte är ovanliga för detta område.
effektivitet
Tänk på att koefficienterna a och p-värdet inte är exakta egenskaper. Oavsett signifikansnivå i statistiken över det studerade fenomenet är det inte en ovillkorlig grund för att acceptera hypotesen. Till exempel, desto mindre värde på a, desto större är chansen att den etablerade hypotesen är betydande. Det finns dock en risk för fel, vilket minskar studiens statistiska effekt (betydelse).
Forskare som enbart fokuserar på statistiskt signifikanta resultat kan få felaktiga slutsatser. Samtidigt är det svårt att dubbelkontrollera deras arbete, eftersom de använder antaganden (som i själva verket är värdena för a och p-värde). Därför rekommenderas det alltid, tillsammans med beräkningen av statistisk betydelse, att bestämma en annan indikator - storleken på den statistiska effekten. Storleken på en effekt är ett kvantitativt mått på styrkans effekt.
